Redefining SOTA
In the machine learning research community, achieving state-of-the-art usually means reporting a single score (percentage accuracy or F1) on a public research dataset. There are two legitimate reasons to report a “SOTA score” in a research paper, besides gaming the system.1
-
A SOTA score may signal to the community that you have “solved” a task that was previously unsolved (like protein folding).
-
A SOTA score may signal to the community that your new method is the “best” method to solve the task, and that the rest of the community (in both academia and industry) should adopt your method as the new standard.
However, a SOTA score in today’s context accomplishes neither of those goals. Because of the way many benchmark datasets are constructed, a high test score (even surpassing human performance) is unlikely to mean that the model is ready for real-world deployment or that the task is “solved.” Furthermore, the ability of neural methods to predictably improve performance with scale means that a single SOTA score is not enough information to decide whether one neural method is better than another.
In light of these two observations (underspecification and neural scaling laws), I think the ML community needs to redefine SOTA. Below, I’ll review some of the literature surrounding underspecification and neural scaling laws, and then make some suggestions about new “metrics for success” that we should adopt as a community.
Underspecification: The Task Is Not Solved
In the early days of machine learning, task performance was often associated with accuracy on a single dataset. “Solving” hand-written digit recognition meant achieving a high accuracy on MNIST, and the Penn Treebank was the gold standard for part-of-speech tagging in natural language processing. However, as the field matured we began meeting the goals we set for ourselves, and we quickly understood that solving the task is not the same as solving the benchmark.
I first experienced this when BERT broke the General Language Understanding Benchmark2, well surpassing human-level performance. Many linguists appropriately asked: does this mean we’ve solved language understanding? The answer was a resounding no. Many papers since have been dedicated to all the ways BERT can be wrong or, worse, right for the wrong reasons.3 4 Many papers pointed out that BERT (as well as later models) can rely on spurious correlations in the data and demonstrated that small, meaningless input pertubations could lead to incorrect answers.5 This is analogous to adversarial examples in image recognition, where adding a small amount of noise can change a correct label to an incorrect label.6
Evaluation datasets are often not powerful enough to differentiate between a model which generalizes and a model which relies on spurious correlations. They may also lack sufficient coverage, such that a high test score obscures problems with the model that would cause problems in production, such as racial/gender bias7 or susceptibility to attack.8 In a recent paper, Google researchers called this problem “underspecification,”9 and point out several examples across the company in which models achieve similar test scores but exhibit widely divergent behaviors when deployed in production. They show that this is a distinct problem from domain-shift, in which the test data distribution is different from the training distribution.
Robust Evaluation
One fix for the problem of underspecification is just to “make the dataset better.” Some interesting work in this direction:
Inspired by “unit tests” in traditional software engineering, Checklist is a framework for testing NLP models along many directions of “linguistic proficiency” by augmenting test examples with deterministic transformations. Examples include negating verbs and replacing nouns in sentences with novel nouns.
A suite of NLP datasets from the Allen Institute for AI. Some datasets are constructed to target specific language capabilities. For example, DROP involves performing discrete reasoning (adding, sorting, counting) over many paragraphs of text.
Tail Chasing
“Tail-chasing” is an attempt at making models more robust to items in the long-tail of the dataset, such as rare words or images. Some other work in this direction:
- What Do Compressed Deep Neural Networks Forget?
- CLESS: Contrastive Label Embedding Self-supervised Zero to Few-shot Learning from and for Small, Long-tailed Text Data
- Large-Scale Long-Tailed Recognition in an Open World
- Generalization through Memorization: Nearest Neighbor Language Models
- Does Learning Require Memorization? A Short Tale about a Long Tail
Neural Scaling: Which Method Is “Best”?
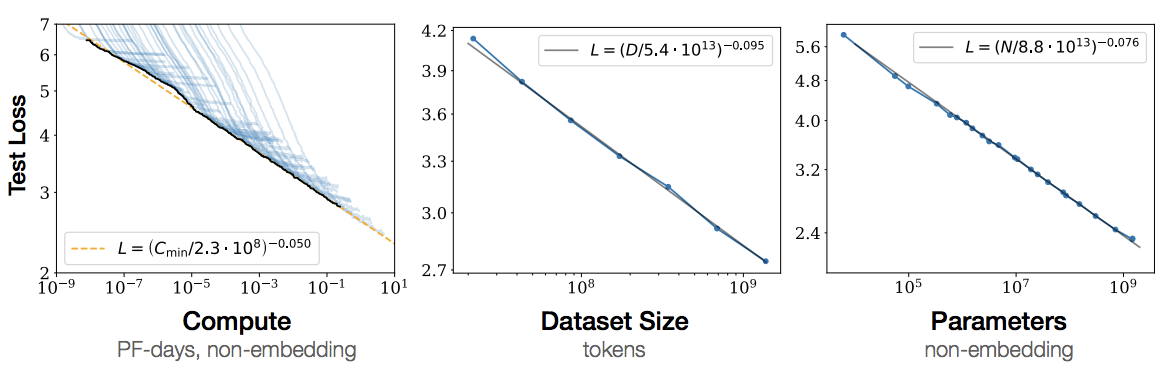
Which neural architecture achieves SOTA on a task depends entirely on the amount of data and compute provided to the architecture. As shown above, performance scales like a power law with data, compute, and parameters. This has now been demonstrated for many data domains, modalities, and neural architectures.10
This means you can make any neural architecture SOTA if you’re willing to spend enough money pouring resources into it. A single SOTA score is not expressive enough to capture this behavior. Consider the following graph showing the performance of machine translation methods with varying amounts of data:11
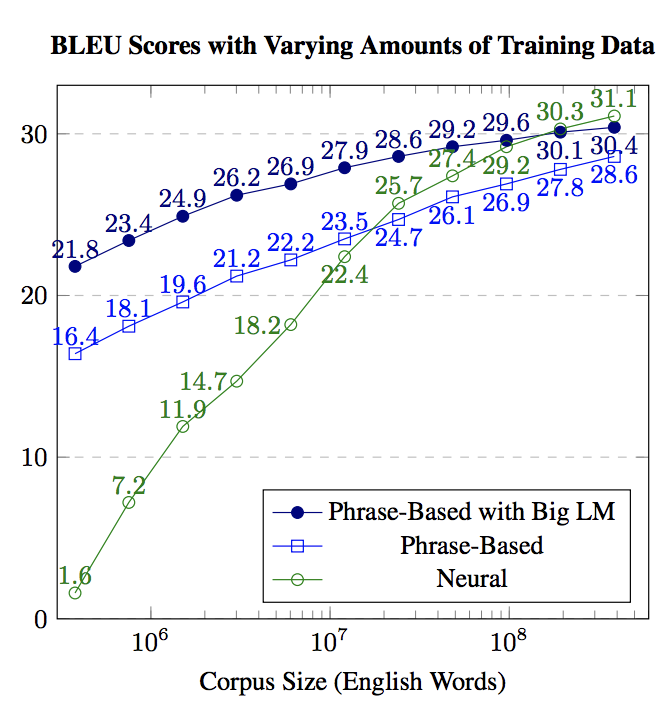
Purely neural methods out-perform other methods when given enough data. However, in low-resource regimes, they fail miserably compared to phrase-based approaches. Depending on how big our training dataset is, a SOTA score might lead us to dramatically different conclusions. A small dataset might give us the impression that phrase-based methods are “better”, whereas a large dataset would lead us to believe neural methods are “better.”
The reality is more nuanced: phrase-based methods have inductive biases that make them better in low-resource scenarios, whereas neural methods scale better with data. And this simple situation doesn’t even take into account the amount of money spent on compute while training each method, and whether that was a bottleneck for either method.
SOTA Scaling, not SOTA Scores
This implies that beating a benchmark dataset is no longer newsworthy (i.e. worthy of publication). Anyone can get a SOTA score if they invest enough money in procuring the data / compute required to get there. What is newsworthy is if you improve the money-to-performance trade-off. That could save billions of parameters or millions of dollars!
In other words, because of neural scaling laws, nearly everyone in ML is working on machine learning efficiency at this point (either compute efficiency or sample efficiency), but no one is measuring success that way!! That’s why ML reviewing feels so broken lately. Here’s a few things we could do right now:
-
Any paper proposing a new “SOTA” neural method needs to report not just the data / compute used to achieve SOTA, but the score achieved at several points of data/compute. The slope of the curve should be better than all other known methods. SOTA scaling is the objective, not SOTA scores.
-
Benchmarks should release pre-determined dataset splits of various sizes, to help fairly measure the sample complexity curves of new methods.
-
Compute / parameters should be measured via a standardized platform, like MLPerf. (But perhaps more streamlined to compare new neural architectures.)
A lot of people complain ML reviewing is broken. I tend to agree. But I also believe that it’s possible to get our act together, as long as we all agree on a paradigm for evaluating new approaches. I think scaling laws, accompanied by robust and strengthened evaluation methods, can help fill that role.
-
The deluge of papers submitted to machine learning conferences has lead to a shortage of quality reviewers who result to heuristics like “reject if not SOTA.” Therefore, many researchers frame their papers as “SOTA score” papers to boost chances of acceptance, even when the paper would be better formulated as a scientific endeavor (or when the paper would not otherwise meet conference standards). Some conferences have started trying to fix this, but progress is slow. ↩
-
“How the Transformers Broke NLP Leaderboards.” 2019. June 30, 2019. https://hackingsemantics.xyz/2019/leaderboards/. ↩
-
Heinzerling, Benjamin. n.d. “NLP’s Clever Hans Moment Has Arrived.” Accessed December 30, 2020. https://bheinzerling.github.io/post/clever-hans/. ↩
-
Marasović, Ana. 2018. “NLP’s Generalization Problem, and How Researchers Are Tackling It.” The Gradient. August 22, 2018. https://thegradient.pub/frontiers-of-generalization-in-natural-language-processing/. ↩
-
“Fall 2019 Natural Language Processing: Matt Gardner (AI2 Irvine).” 2019. Youtube. December 31, 2019. https://www.youtube.com/watch?v=k7d_Nnv_shw. ↩
-
Ilyas, Andrew, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. 2019. “Adversarial Examples Are Not Bugs, They Are Features.” arXiv [stat.ML]. arXiv. http://arxiv.org/abs/1905.02175. ↩
-
“NeurIPS 2020 : You Can’t Escape Hyperparameters and Latent Variables: Machine Learning as a Software Engineering Enterprise.” n.d. Accessed December 30, 2020. https://nips.cc/virtual/2020/public/invited_16166.html?utm_campaign=NLP%20News&utm_medium=email&utm_source=Revue%20newsletter. ↩
-
Chen, Xinyun, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. 2017. “Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning.” arXiv [cs.CR]. arXiv. http://arxiv.org/abs/1712.05526. ↩
-
D’Amour, Alexander, Katherine Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen, et al. 2020. “Underspecification Presents Challenges for Credibility in Modern Machine Learning.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/2011.03395. ↩
-
https://arxiv.org/abs/2010.14701 ↩
-
Koehn, Philipp, and Rebecca Knowles. 2017. “Six Challenges for Neural Machine Translation.” In Proceedings of the First Workshop on Neural Machine Translation, 28–39. Stroudsburg, PA, USA: Association for Computational Linguistics. ↩