RETRO Is Blazingly Fast
When I first read Google’s RETRO paper, I was skeptical. Sure, RETRO models are 25x smaller than the competition, supposedly leading to HUGE savings in training and inference costs. But what about the new trillion token “retrieval database” they added to the architcture? Surely that must add back some computational costs, balancing the cosmic seesaw?
Apparently not. After running benchmarks for myself, at scale, I am convinced that RETRO is indeed BLAZINGLY fast. RETRO is so fast and cheap, in fact, that I cannot fathom why anyone would choose to do language modeling without retrieval.
RETRO Overview
To achieve similar performance to bigger models like OpenAI’s GPT-3, RETRO adds an auxiliary “database” of text data, which is queried both during training and inference. This database needs to be HUGE (> 1T tokens!), or else it doesn’t really help.
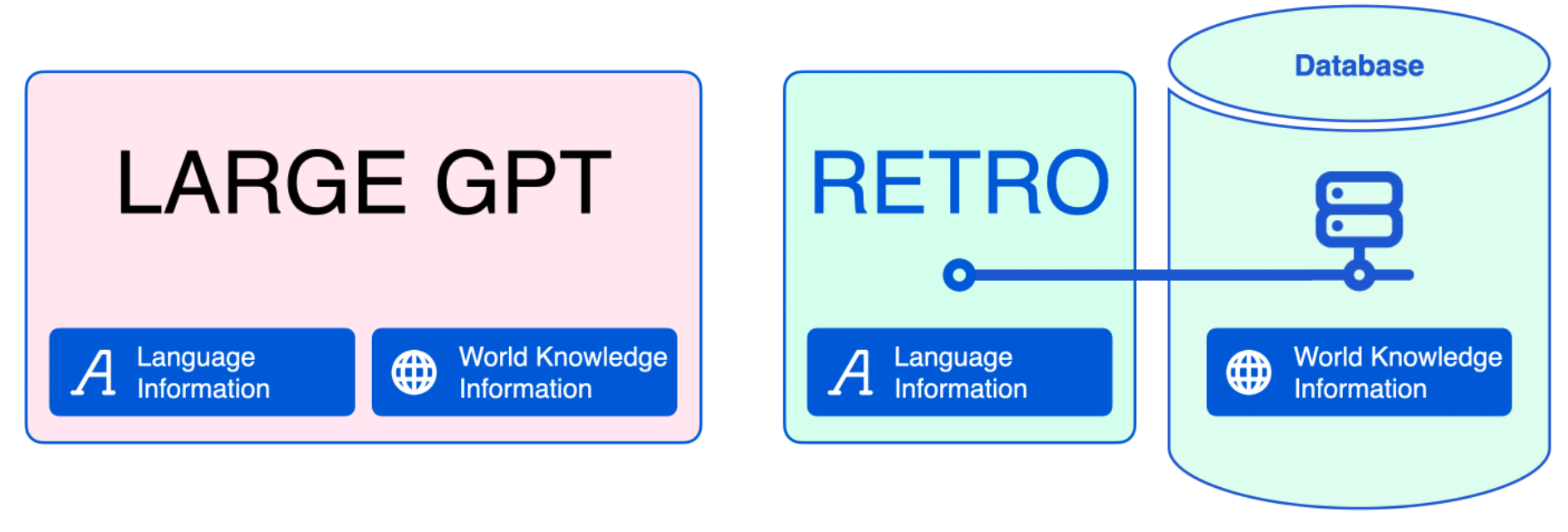
https://jalammar.github.io/illustrated-retrieval-transformer/
We’ll see that making and querying this database is orders of magnitude cheaper than training / inference on big neural networks. In this post I’ll briefly describe how the database is constructed and some benchmarks I did while making a database of The Pile, which I’m happy to share by request.1
I used a fork of LucidRain’s RETRO-pytorch implementation, which has been modified to handle some scale things like parallelization of jobs. Also thanks to my employer, Latitude, for giving me the compute to do these experiments.
The Pile
I used The Pile as my benchmark dataset, which is an open-source dataset provided by EleutherAI. It weighs in at around 830 GB of raw text. To get a sense of how much data this is, notice the “Wikipedia” section in the source breakdown below:
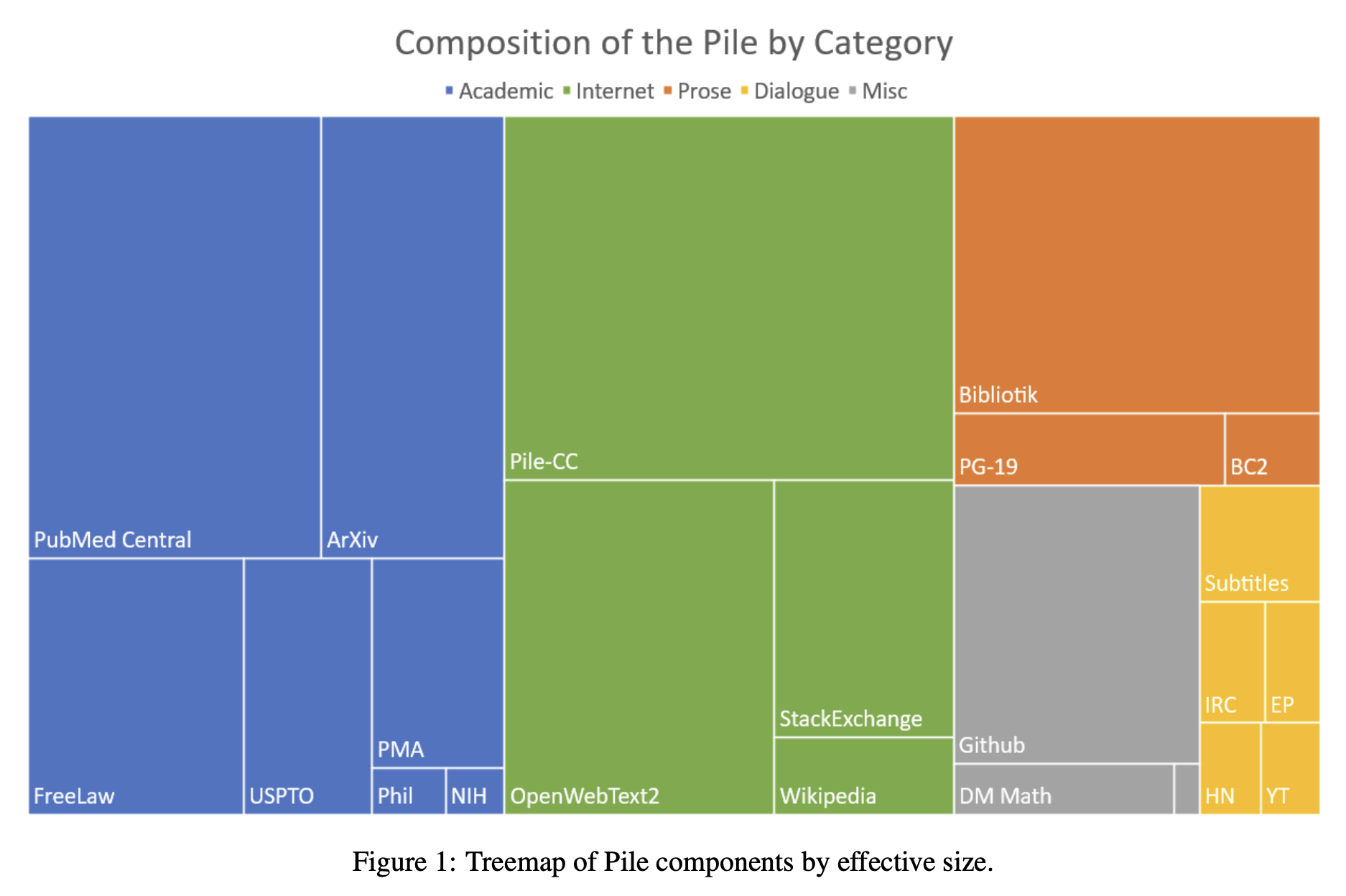 https://arxiv.org/abs/2101.00027
https://arxiv.org/abs/2101.00027
Building The Database
Building a database of The Pile was surprisingly cheap by neural network training standards (~$1k total). It broadly involves three steps:
- Tokenize the data and split it into chunks of 64 tokens each
- Embed the chunks with BERT
- Index the embeddings with a MIPS library (FAISS, SCANN, etc.)

Tokenization
Tokenization takes around 1.9 min / 1M chunks on your standard CPU core. The Pile ends up being around 5.8B chunks (370B tokens), so that means you’re looking at ~180 hours of CPU time to tokenize, which you can easily parallelize down to only a few hours of wall time.
With a CPU core on the cloud going for around $0.03 / hour, that means you’ll spend less than $10 on tokenization.
Embedding
BERT embedding is the most expensive step. On an RTX A5000, BERT embedding takes around 10 minutes per 1M chunks.2 That’s around 1k GPU hours to embed The Pile, which again is very easy to parallelize. This cost around $1k on Coreweave.
Note that BERT embeddings are around 3 KB each on disk. (768 float32s). 5.8B of them takes up about 16 TB on disk, so watch out for that. (Disk space is cheap.)
MIPS Indexing
The MIPS index is the reason the RETRO database lookup is so fast. MIPS stands for maximum inner-product search, which is when you search a database of vectors for the ones closest to your “query” vector. In RETRO, we use this to look up chunks of text from The Pile that are similar to our input.
Companies like Google and Facebook have been doing MIPS at scale for over a decade, so there’s been a huge amount of research optimizing the heck out of this stuff. Google’s RETRO used their new library, SCANN, but I ended up using the more mature FAISS library from Facebook, which has a near identical implementation of the algorithm used by SCANN.
I tried to get the FAISS configuration as close as possible to what Google used in the RETRO paper. FAISS indices can be built using “factory strings” which specify which types of indices to build and how to compose them. My factory string is OPQ16_64,IVF1048576_HNSW32,PQ16x4fs
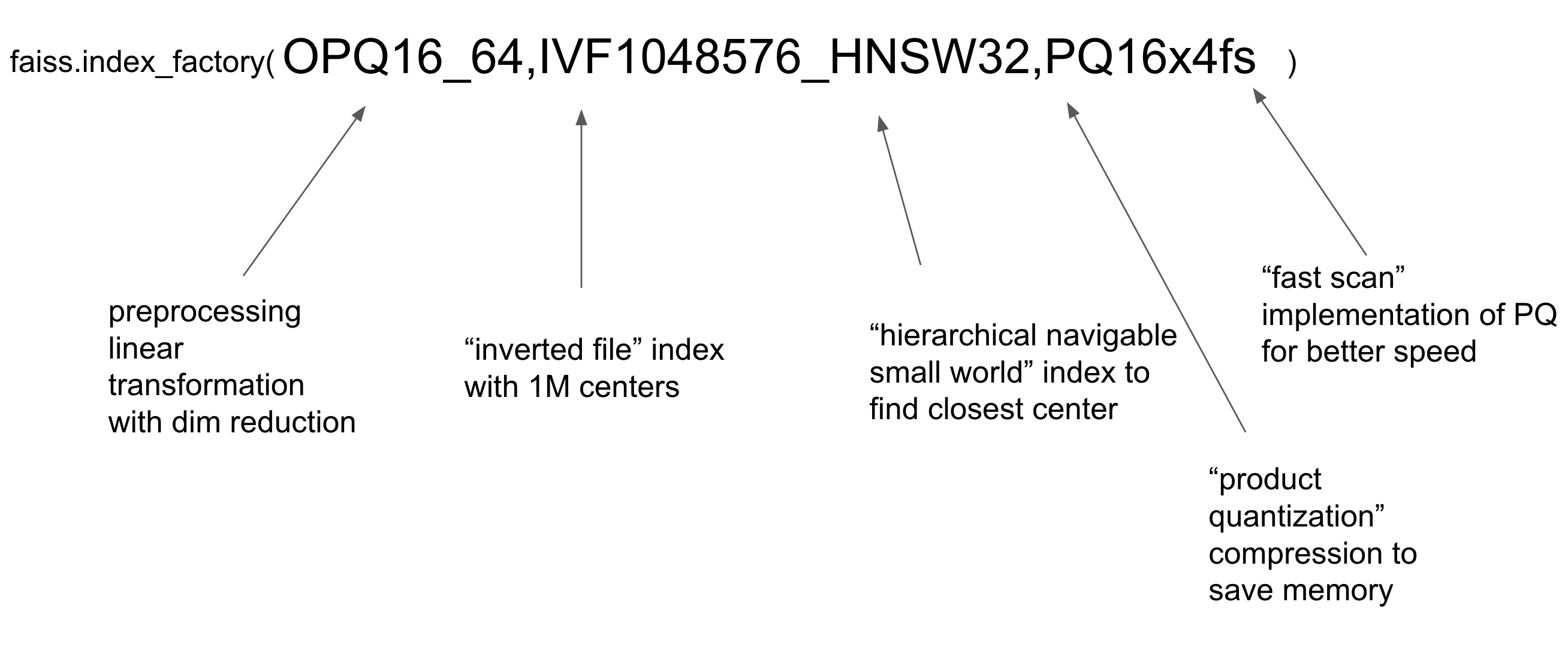
Check out Pinecone’s wonderful faiss tutorial and index factory explainer for more information on the optimization tricks used by FAISS and similar libraries. I also enjoyed this tutorial on how Product Quantization works under the hood. There are still some things I could tune here to optimize the speed / accuracy trade-off, but I’ll leave that for future me.3
Index Training
One particular trick used by FAISS (the inverted file structure) requires taking a small percentage of the data (64M embeddings) and using them to train the index. On a V100 GPU, this only took around 4 hours, so the cost was negligible.
Once the index is trained, we can add all the embeddings to the index, compressing them for lookup. This takes longer than you’d expect (around 192 CPU hours) but ultimately only represents a cost of <$30.
Querying the Database
Now that we’ve built the database, how long does it take to query it? Personally, I would have been happy with anything < 100ms, since that would have represented a marginal increase in existing generation times. For reference, here’s how long it takes to generate around 50 tokens with various language models:
- GPT-J (6B): ~3s
- AI21 Grande (17B): ~4s
- GPT-NeoX (20B): >4s
- AI21 Jumbo (175B): ~6.5s (x ~6 GPUs)
In practice, our FAISS index takes between 2 and 40 ms,4 based on my manual testing. That’s… really fast. Embedding the query with BERT takes an additional 10 ms on a CPU. Altogether, the cost of querying the database during inference and training has a totally neglibile impact on total cost.
Qualitative Results
query: The old man wept, for he knew that his end had come. The waves of time washed over him.
result 1: she faded from them, as the bright snow, that none may keep, melts in our very hands. A murmur of farewell came to his ears, - - no more. She was gone. He would have followed, but Charon, now on guard, drove him back. Seven days he lingered there between the worlds
result 2: but as I tarried? And when I could no more, I did go, and I did stay, and I did steward. Stayed at the station. The ravens did raven. The steward did steward. But one thing mattered. The Spirit did Spirit. And the word remained. For
query: In today's news, Miley Cyrus was caught shoplifting from a clothing store on Hollywood Boulevard.
result 1: ##s in Texas. The child, whose name was not released, boarded the Techno Jump Ride with her 8 - year - old brother at the RodeoHouston carnival around 2 p. m. Wednesday, according to local affiliate KTRK. RodeoHouston is a popular local attraction. Witnesses told
result 2: [CLS] Is this the worst airplane loader in the world? Proof can be found in a year - old YouTube video that just surfaced via Reddit. In it, an unidentified freight handler can be seen haphazardly tossing packages from a flat bed onto a conveyor belt at China's Guangzhou Airport. Capt
query: Hey Betty! Thanks for getting back to my email. Are we still on for Saturday?
result 1: 20 AM I just recd. an email from gary sinclair and it got me thinking about all the great people and good freinds of VR - 24. I know a few of you have emailed me in the past and I didnt respond but I will to all future emails. After
result 2: starmail. com Subject : oops Soz babe didnt mean to sned that!!!! Was trying to email a mate on my phone and been drinkin ps hop u r ok I close the laptop and I sit for a long time in silence. As I do, I examine the happy, laughing
The Hidden Cost of CPU RAM
The FAISS index is not totally cost free. The index itself ends up being big, requiring around 176 GB of RAM to query, which costs about $0.88 per hour on your average cloud provider.
However, this allows you to drastically reduce your GPU usage. Say, for example, you need 5 GPUs running in parallel to do inference on a 175B parameter model, which costs around $6 an hour. By adding an extra $0.88 / hour in CPU RAM, you can reduce the number of GPUs you have to run to just 1, saving around $5 / hour in GPU costs. I’d take that trade any day.
This also applies to models that are already using a single GPU. By shrinking your model with RETRO’s database, requests get served faster, meaning more GPU bang for your buck. Instead of serving 60 req / hour on a single GPU, you’re serving 600+, just for a little extra CPU RAM.
Update (7/6/22) - I’ve been informed that FAISS has the ability to memory map an index, which allows you to read it directly from disk instead of allocating RAM for it. This is slightly slower, of course, but probably worth the trade. (Thanks rom1504.)
Conclusion
At first I was skeptical, but upon closer inspection it seems like RETRO is indeed a HUGE cost savings over existing LM approaches. These cost savings seem to boil down to the fact that MIPS is super optimized by existing libraries and only requires more CPU RAM to use. Based on these observations, I can’t imagine why anyone doing language modeling in production would choose to do it without retrieval.
-
I tried uploading some of it to Huggingface, but even the compressed FAISS index file exceeded the max 50 GB file size. The tokens themselves are over 1.5 TB. Feel free to shoot me an email and I’ll get you a copy. Update (5/11/23) - I no longer work at Latitude and therefore no longer have access to this index. Sorry! ↩
-
Naively, I didn’t do much optimization here. I suspect the bottleneck is probably getting data off disk to the GPU, not the computation speed. ↩
-
Specifically I’m not certain we need to be so aggressive with the dimensionality reduction during pre-processing. (768 dims → 64.) Because of the way PQ works, I’m pretty sure I could get away with less dimensionality reduction and improve accuracy. ↩
-
For k=5, with the IVF nprobe also set to 5. (Which seems to be a standard setting, but could be tuned to trade speed / accuracy.) ↩